


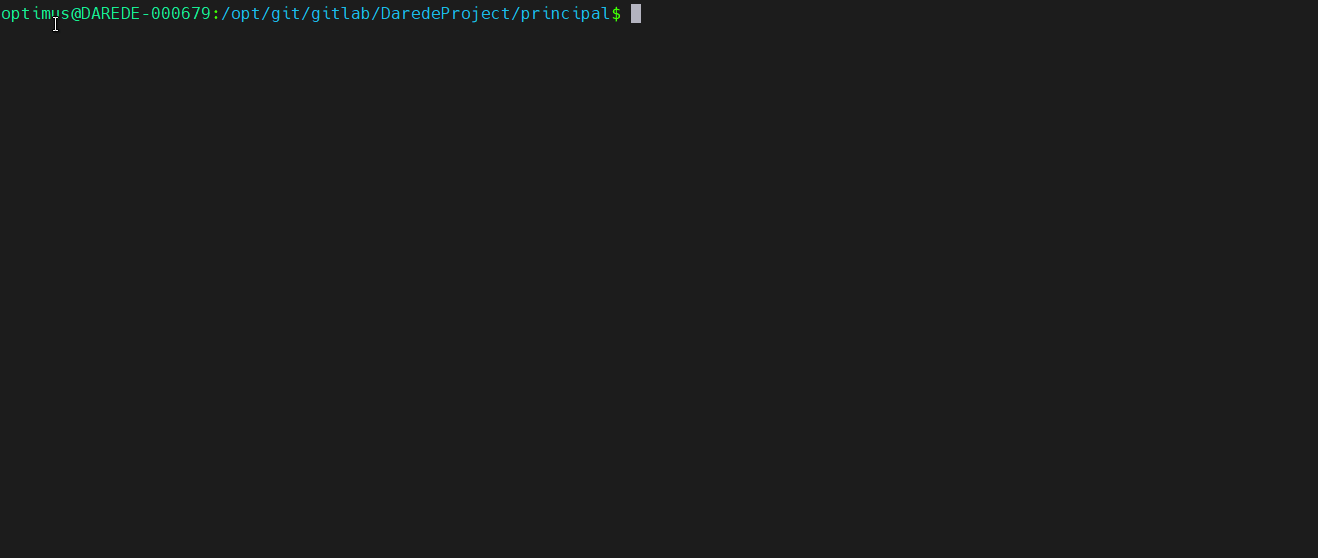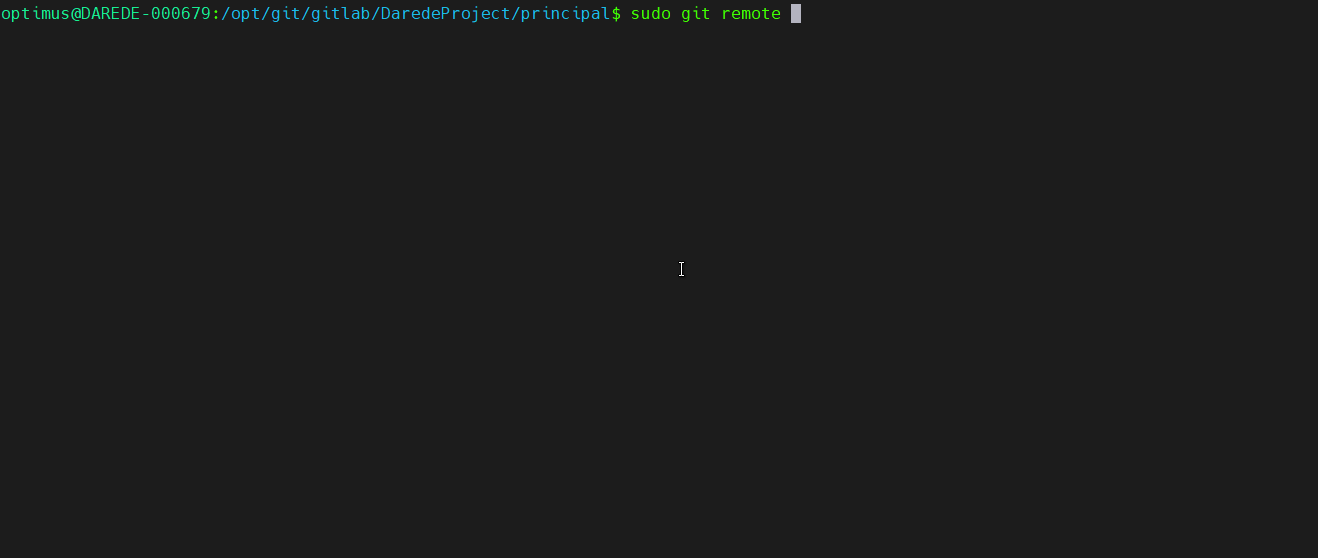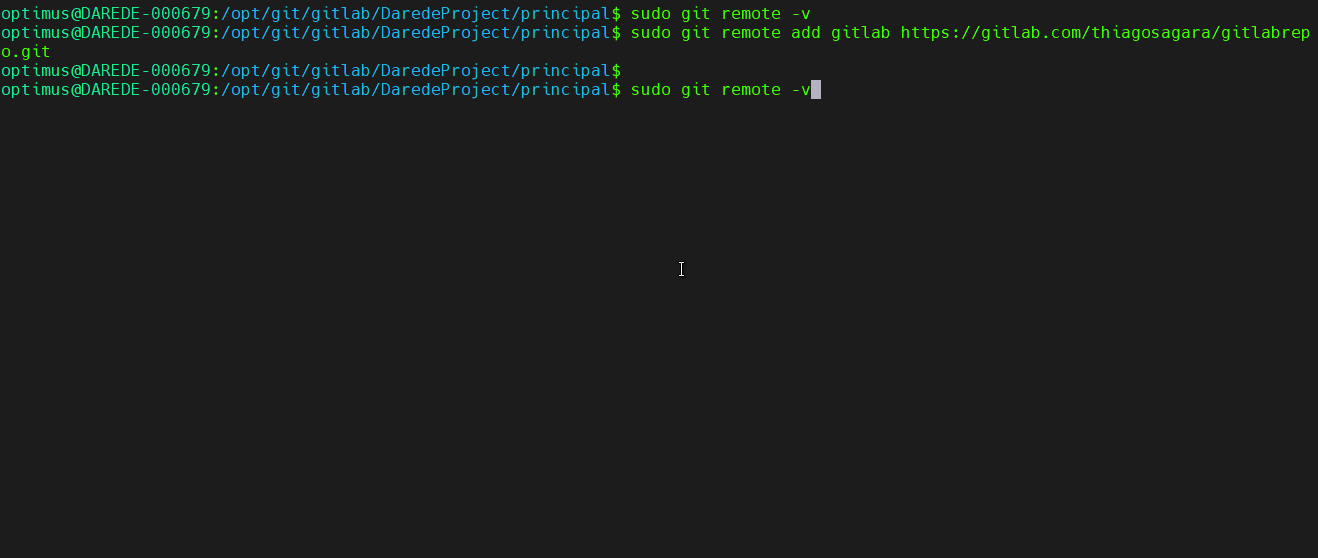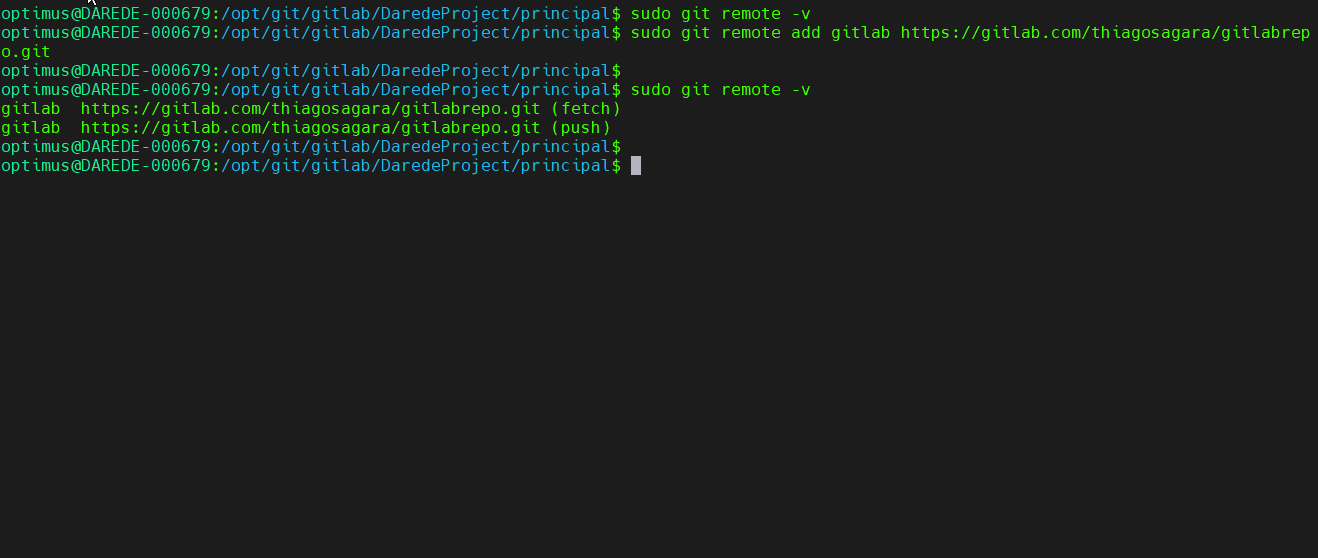
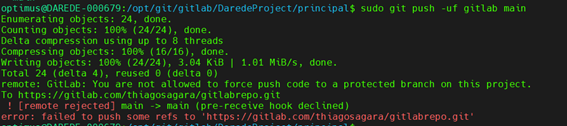

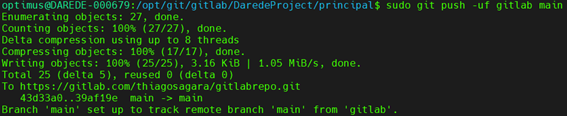

Thiago Marques
Technical Account Manager
Technical Account Manager da Darede, formado em Rede de Computadores e pós-graduado em Segurança da Informação. Possui ampla experiência em Datacenters e Service Providers, além de ser um entusiasta em DevOps e mercado financeiro.





